
-
Research
- Experts
In The News
View All
Healthcare IT interviews Dr. Kathleen Unroe
Kathleen Unroe, M.D., MHA, M.S., was interviewed by Healthcare IT...
Influence
View All
Screening for Food Insecurity: US Preventive Services Task Force Recommendation Statement
Published in JAMA Here is a link to the article....
- Opportunities
- Experts




How can I learn more about the data?
You can learn more about the data from our Data Guide. We also have an online Data Catalogue.
Why does INPC cover 18 million patients when the IN population is 6.76 million?
The Indiana Network for Patient Care has been in existence since 1994 and represents all individuals who have passed through the participating health systems in that time –- so nearly 30 years of individuals treated in participating Indiana hospitals. This means the database contains people who have died, those who have migrated in and out of the State, and even a few who may have been passing through or for some reason came to Indiana for care. That said, while INPC contains data on 18 million patients, not all the patients have quality data or depth of data. Depending on why or where they were seen, we may only have a limited piece of clinical information on the individual (such as a lab test or one encounter).
How are patients matched across systems?
The matching algorithm that is utilized for the health information exchange is very conservative and errs on the side of not matching. First and foremost, INPC is a clinical tool. It is utilized by providers to review more complete past histories on their patients. Because of the clinical mission, INPC’s algorithm is conservative to avoid negative clinical outcomes. For example, you would not want to match “John Smith” with diabetes to “John Smith” who does not have diabetes because it would likely alter how a provider treats that patient. If the algorithm is not certain it is the same person, it creates a new ID. The matching process does continue to run, so if a new piece of information becomes available that convinces the algorithm it is the same person, it merges the IDs. However, we suspect there is a decent number of individuals who should be matched, but are not.
This also explains why some people may only have limited clinical data — they might have more, but it hasn’t matched for some reason. If increased match rates is important for your research project (and your research can tolerate a more aggressive matching strategy), there are other matching strategies that RDS can employ.
Ultimately, if data depth is important, it will be critical to define your cohort well up front. For more about how to do that, check out the short video embedded on this page.
What is NLP?

Did you know that as much as 80% of clinical data is locked away in unstructured documents of electronic health records systems?
The clinical observations in these notes are so valuable for studying health care quality and improving patient care that Regenstrief’s Data Services team built a tool called nDepth™ just to unearth them.
nDepth™ indexes and searches vast collections of free-text data for to create sets of characteristics, or phenotypes, that identify a specific condition or population.
This machine learning process — creating the algorithms that mine data from the free text and then using a human gold standard to teach the algorithms to improve — is NLP, or natural language processing. And it can bring meaningful clinical content to your fingertips in a fraction of the time.
The best part about pursuing natural language processing with Regenstrief Data Services is our depth of experience. Not only do we offer the services of data analysts specifically trained in nDepth™ searches, but those analysts work directly with the developers who created this and many more custom solutions.
How do I gain access to the data?
Regenstrief is the Honest Data Broker for the Indiana Network for Patient Care (INPC) as well as two hospital systems. If you’d like to utilize the data for research purposes, you can request a data set from Regenstrief Data Services.
What's the first step in the data request process?
We highly recommend you start with a feasibility request to make sure the data supports your research question. Feasibilities are free to researchers on campus.
What is needed in order to access the data?
If you are ready to start your data request, you’ll need to have an approved IRB from either IU, Purdue, or Notre Dame or an approved reliance request from one of those institutions. We also suggest that you speak with a representative from RDS to make sure any financial details are worked out.
What is the cost of the data?
RDS doesn’t sell the data but we do require the cost of the analyst’s time be covered. Much like you would include a research assistant on a grant, the effort involved in your request will need to be covered. If this is a small project, we utilize an hourly rate. If this is a larger grant, we’re happy to be included as effort if appropriate. Email askrds@regenstrief.org if you would like us to provide an estimate for your project. We are happy to do so!
What can I expect when working with RDS on initial study feasibility?
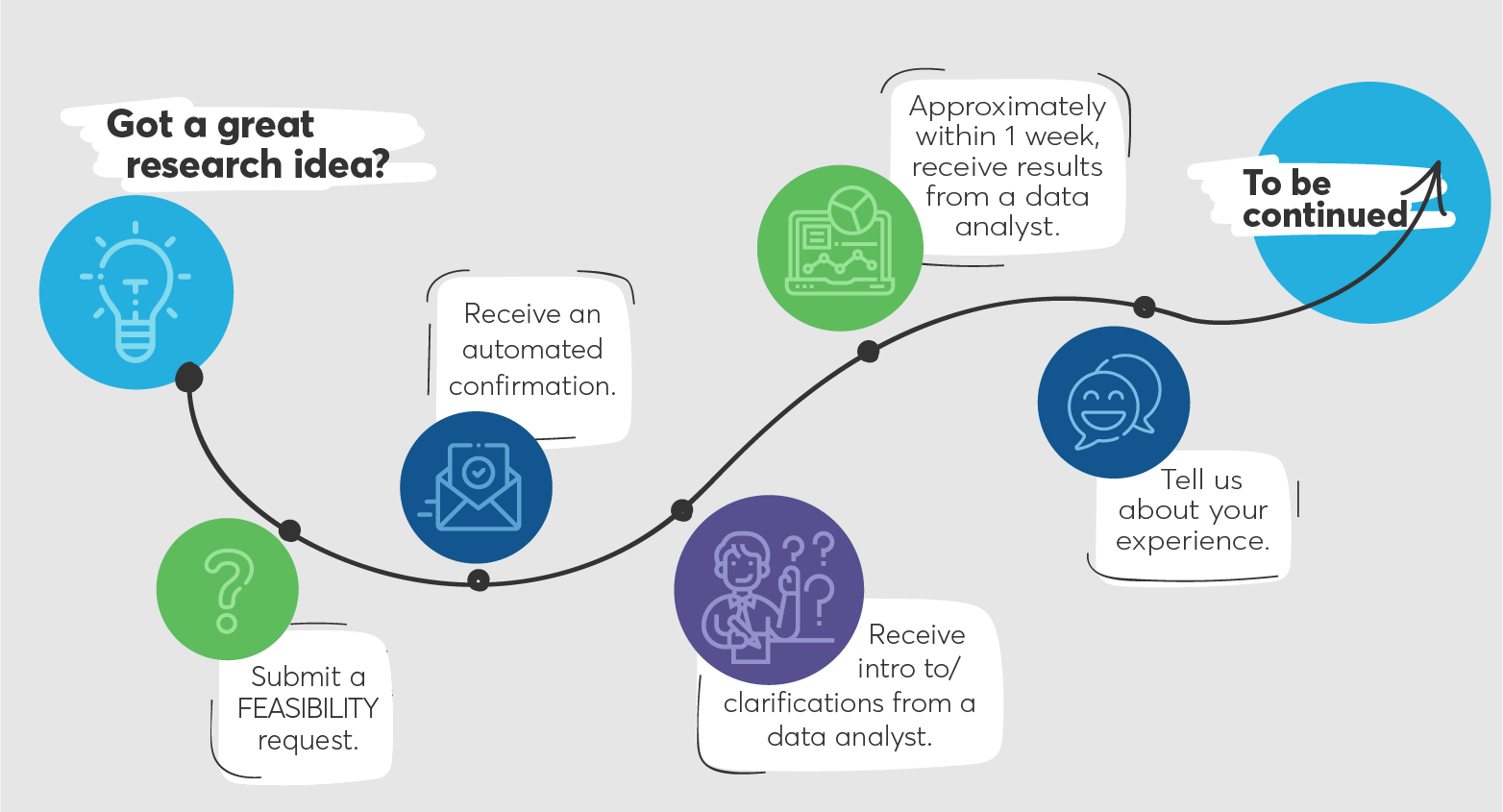
How do I cite Regenstrief for data used in my paper?
“Regenstrief Institute, Inc.’s participation in this project is acknowledged for access to and expertise in data management.”